
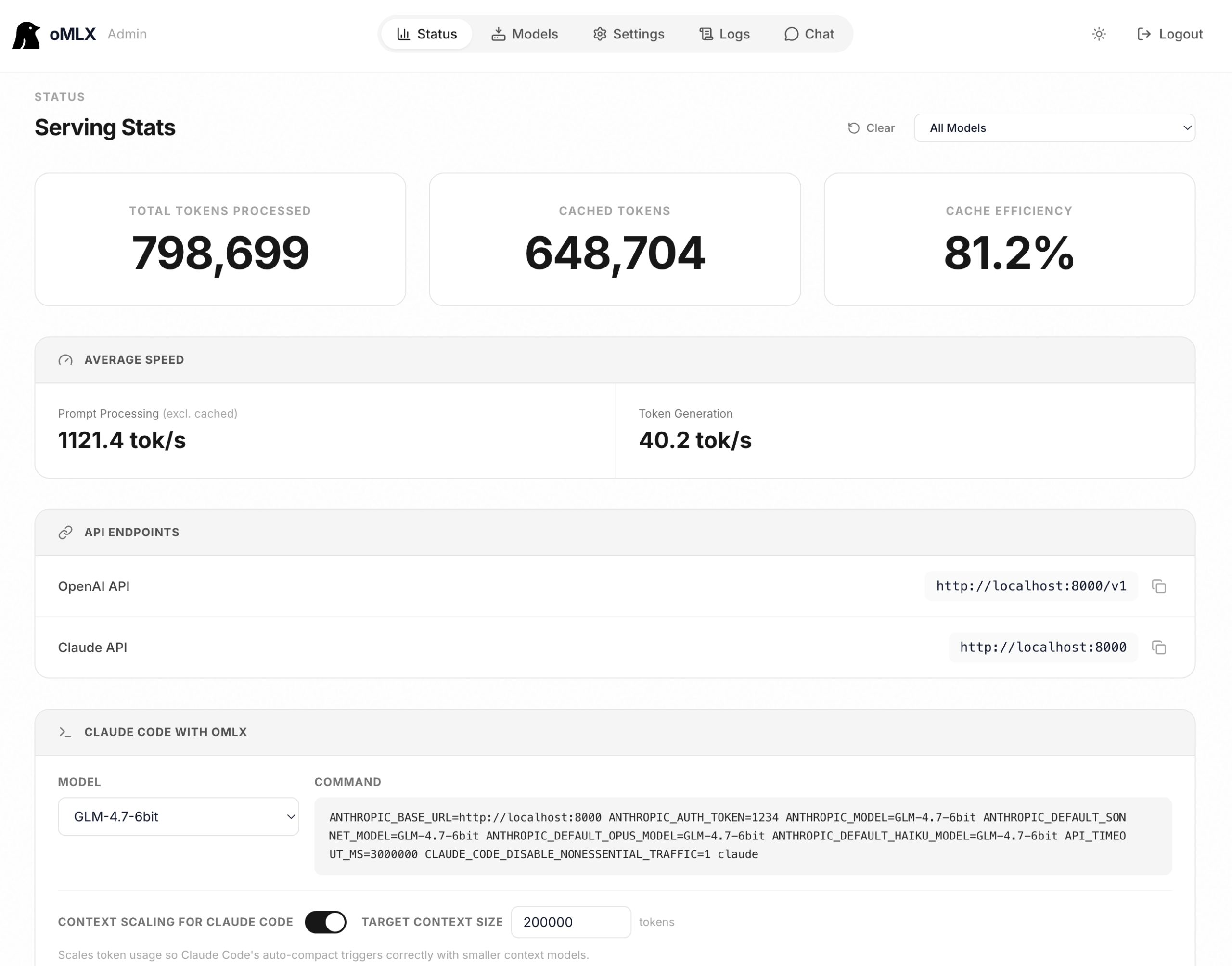
oMLX.AI 是专为 macOS 设计的原生 MLX 服务器,旨在充分利用 Apple Silicon 的计算能力,提供极速的本地大型语言模型(LLM)推理体验。该平台通过融合智能 SSD 缓存与连续批处理技术,解决了传统内存缓存的局限性,实现了低延迟多模型推理。开发者无需依赖云端,即可在本地环境中高效测试、部署和优化 AI 模型,适用于编码辅助、内容生成及多模态任务等场景。
对于 macOS 用户而言,一款能够充分发挥 Apple Silicon 芯片潜力的本地大模型推理引擎显得尤为重要。
oMLX 正是为解决这一痛点而生的开源项目。它是一个专为 macOS 原生设计的 MLX 服务器,提供 LLM 大语言模型推理服务,具有智能缓存功能,针对编码代理的实际工作方式进行了深度优化。
🎯 oMLX 的核心价值:让 Claude Code、OpenClaw 和 Cursor 等工具能在 5 秒内响应,而非传统的 90 秒。这意味着开发效率的质的飞跃!
核心功能特性

技术架构详解
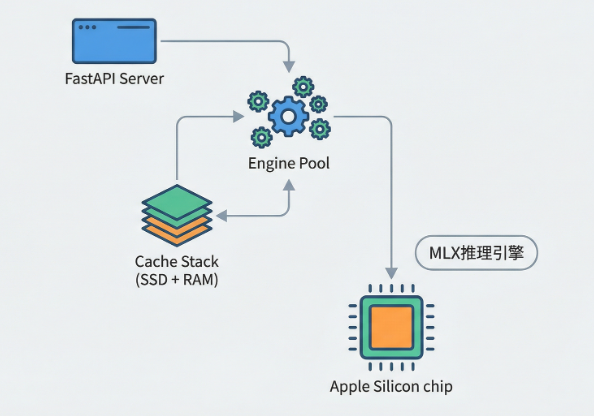
oMLX 的技术架构采用分层设计,核心组件包括:
- FastAPI Server:提供 OpenAI 和 Anthropic API 兼容接口
- EnginePool:多模型管理,支持 LRU 驱逐、TTL、手动加载/卸载
- ProcessMemoryEnforcer:总内存限制,防止 OOM
- Scheduler:FCFS 调度,可配置批处理大小
- Cache Stack:分层 KV 缓存(内存热缓存 + SSD 冷缓存)
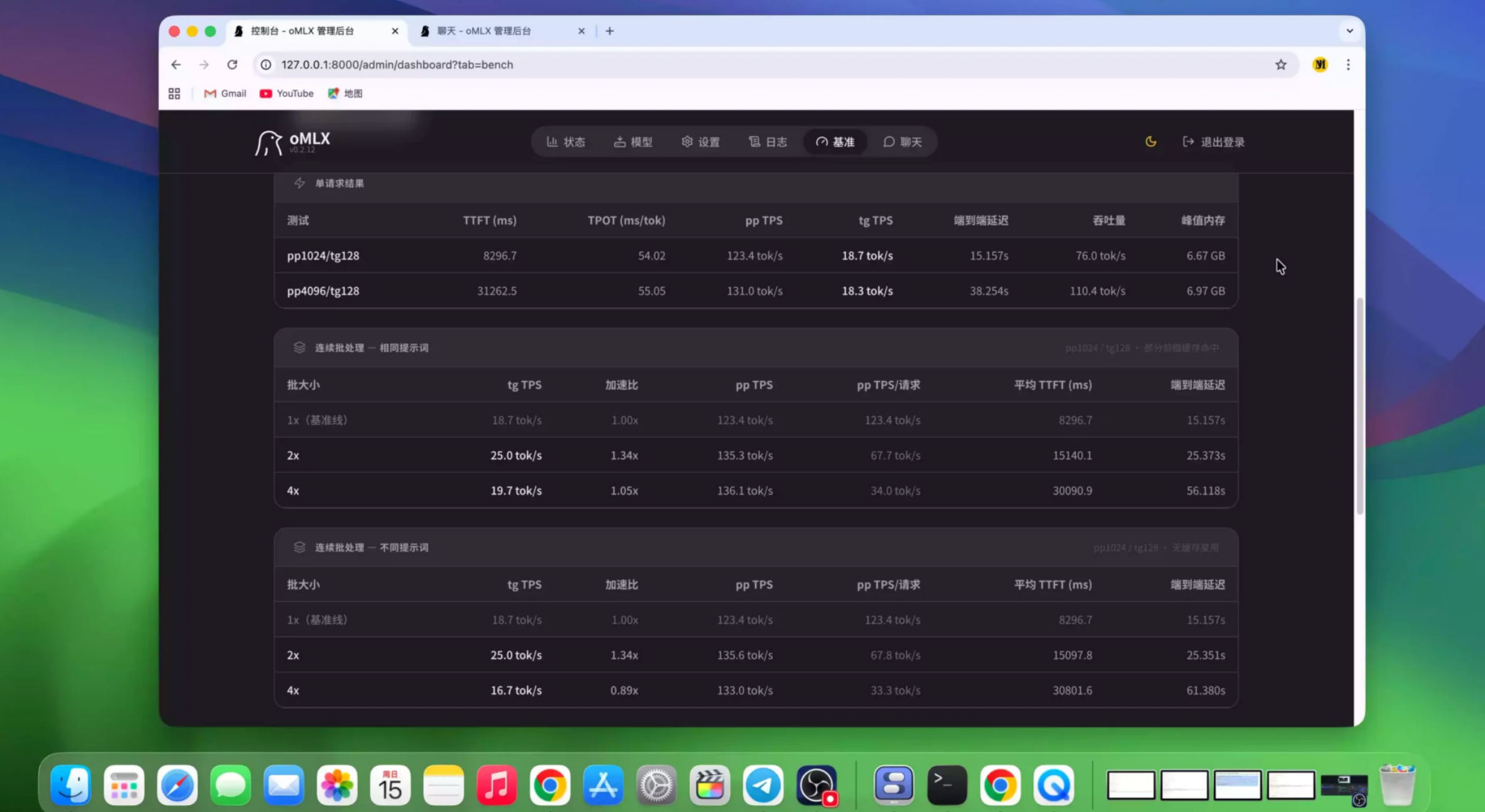
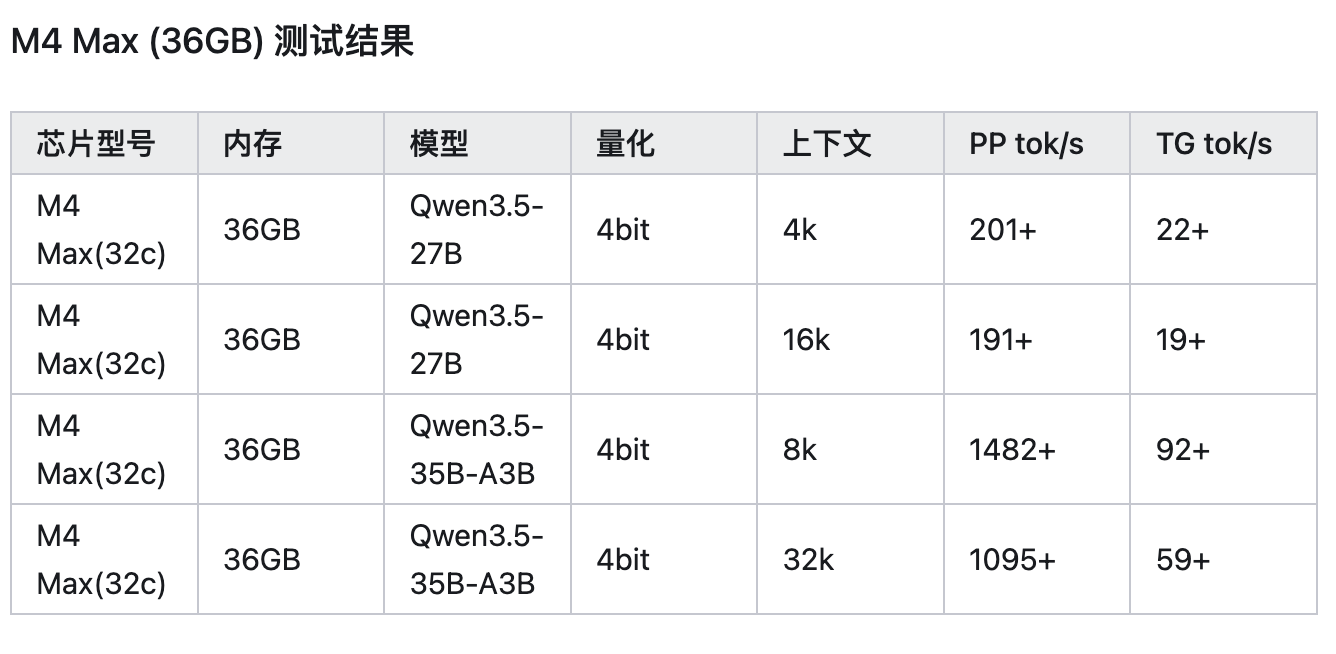
实测性能数据
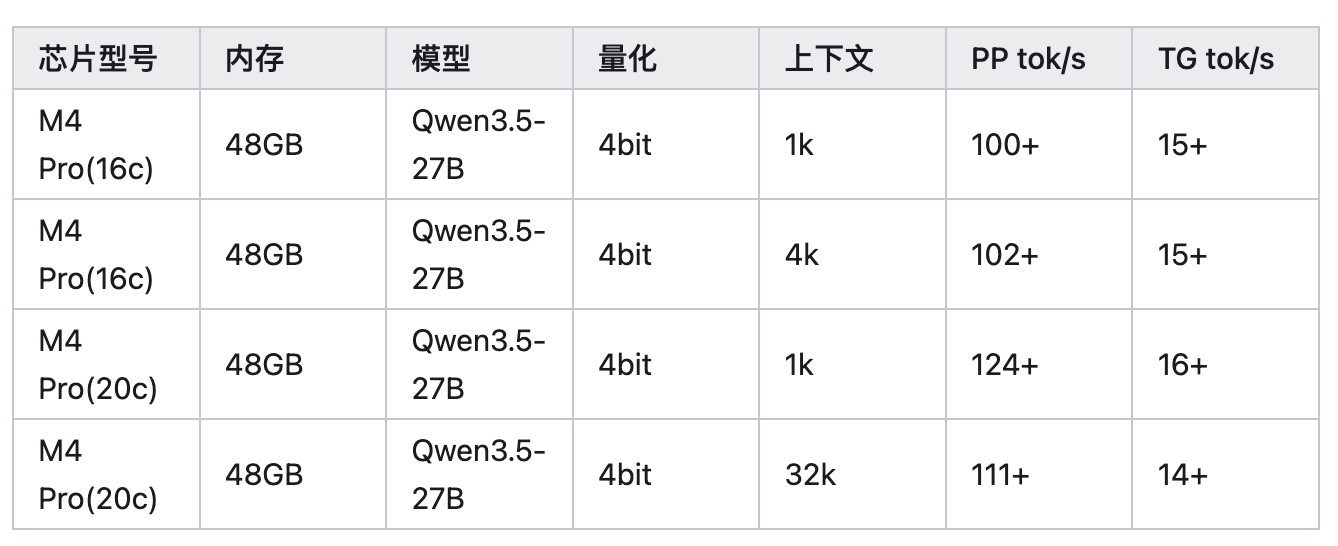
oMLX 官方基准测试收集了大量社区用户的测试数据。以下是不同 Apple Silicon 芯片的实测表现:
M4 Pro (48GB) 测试结果
安装与配置
系统要求
- 芯片:Apple Silicon (M1/M2/M3/M4/M5)
- 系统:macOS 15.0+ (Sequoia)
- 内存:最低 16GB(推荐 64GB+)
- Python:3.10+
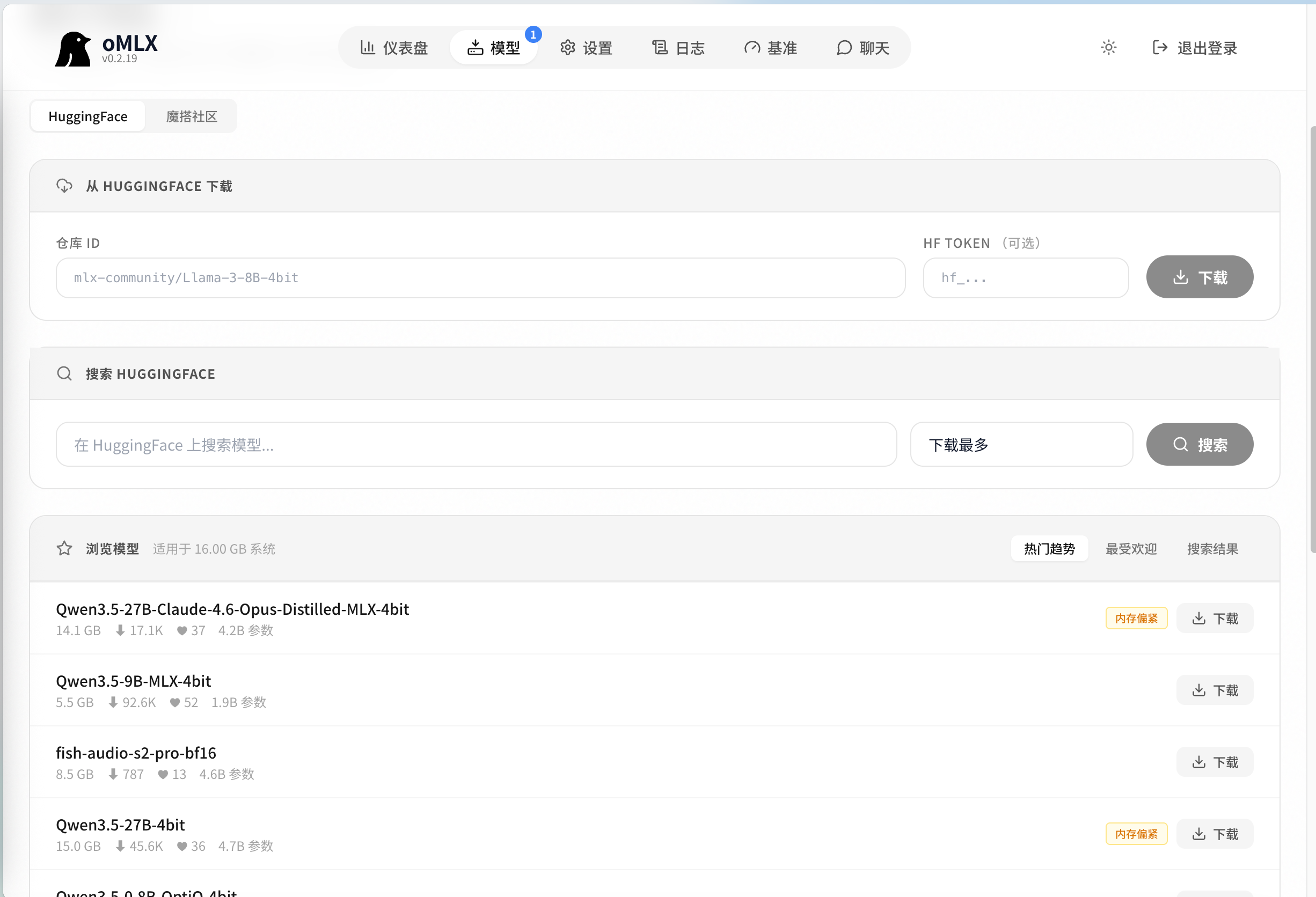
安装方式一:macOS 应用(推荐)
方式 A:macOS 应用(推荐)
- 从 GitHub Releases 下载 DMG 文件
- 拖动到 Applications 文件夹
- 首次启动时显示欢迎屏幕,引导完成以下步骤
- 设置模型目录
- 启动服务器
- 下载第一个模型
安装方式二:Homebrew
# 添加 Tap 并安装
brew tap jundot/omlx https://github.com/jundot/omlx
brew install omlx
# 升级到最新版本
brew update && brew upgrade omlx
# 作为后台服务运行(崩溃自动重启)
brew services start omlx
# 可选:安装 MCP 支持
/opt/homebrew/opt/omlx/libexec/bin/pip install mcp安装方式三:从源码安装
# 克隆并安装
git clone https://github.com/jundot/omlx.git
cd omlx
pip install -e . # 仅核心功能
pip install -e ".[mcp]" # 带 MCP 支持
# 启动服务
omlx serve --model-dir ~/models使用教程
启动服务器
通过命令行启动 oMLX 服务器:
# 基本启动
omlx serve --model-dir ~/models
# 启用 SSD 缓存
omlx serve --model-dir ~/models --paged-ssd-cache-dir ~/.omlx/cache
# 设置内存限制
omlx serve --model-dir ~/models --max-process-memory 80%💡 提示:可以复用现有的 LM Studio 模型目录,无需重新下载所有模型。
API 调用示例
Chat Completions
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "model-name",
"messages": [{"role": "user", "content": "你好!"}]
}'流式输出
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "model-name",
"messages": [{"role": "user", "content": "写一首诗"}],
"stream": true
}'Anthropic API
curl http://localhost:8000/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: your-key" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-20250514",
"max_tokens": 1024,
"messages": [{"role": "user", "content": "解释量子计算"}]
}'集成 Claude Code / Codex/OpenCode/OpenClaw
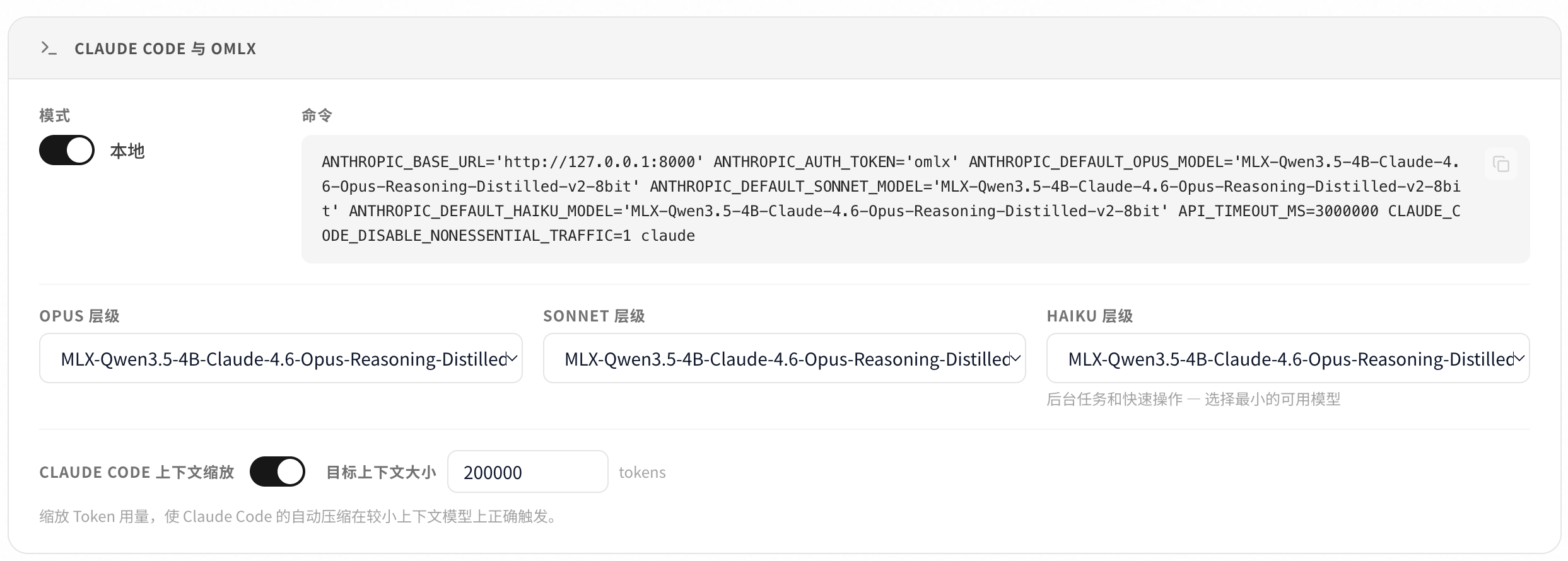
oMLX 提供一键配置生成器,简化了与主流开发工具的集成:
- 打开 Web 管理面板 (http://localhost:8000/admin)
- 选择要使用的模型
- 点击 “Integrations” 选项卡
- 一键复制配置命令
- 粘贴到对应工具的配置文件
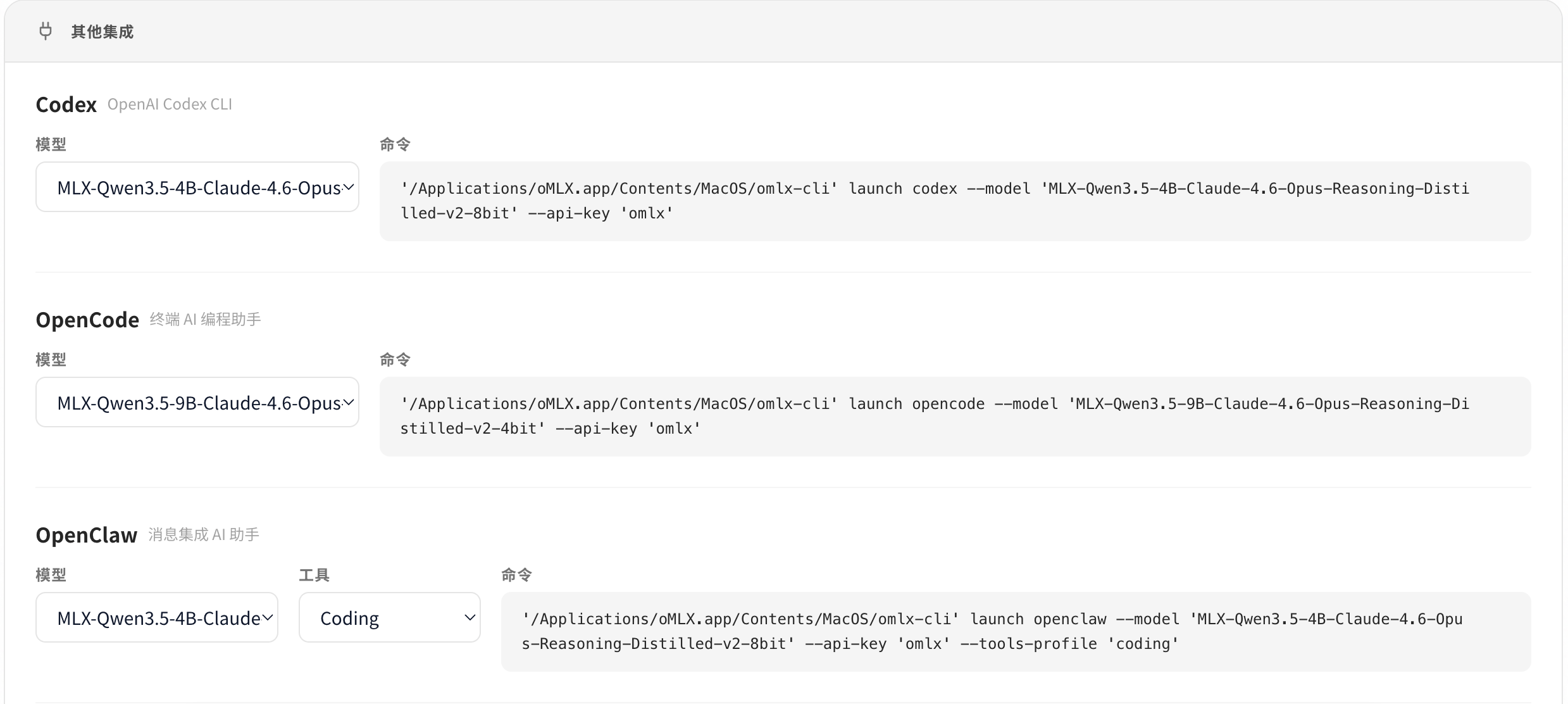
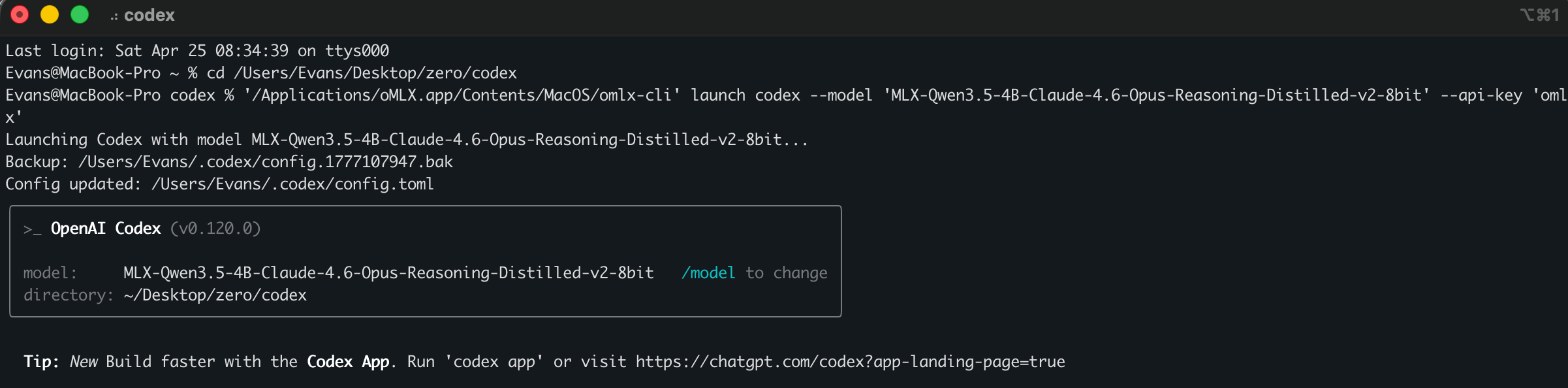
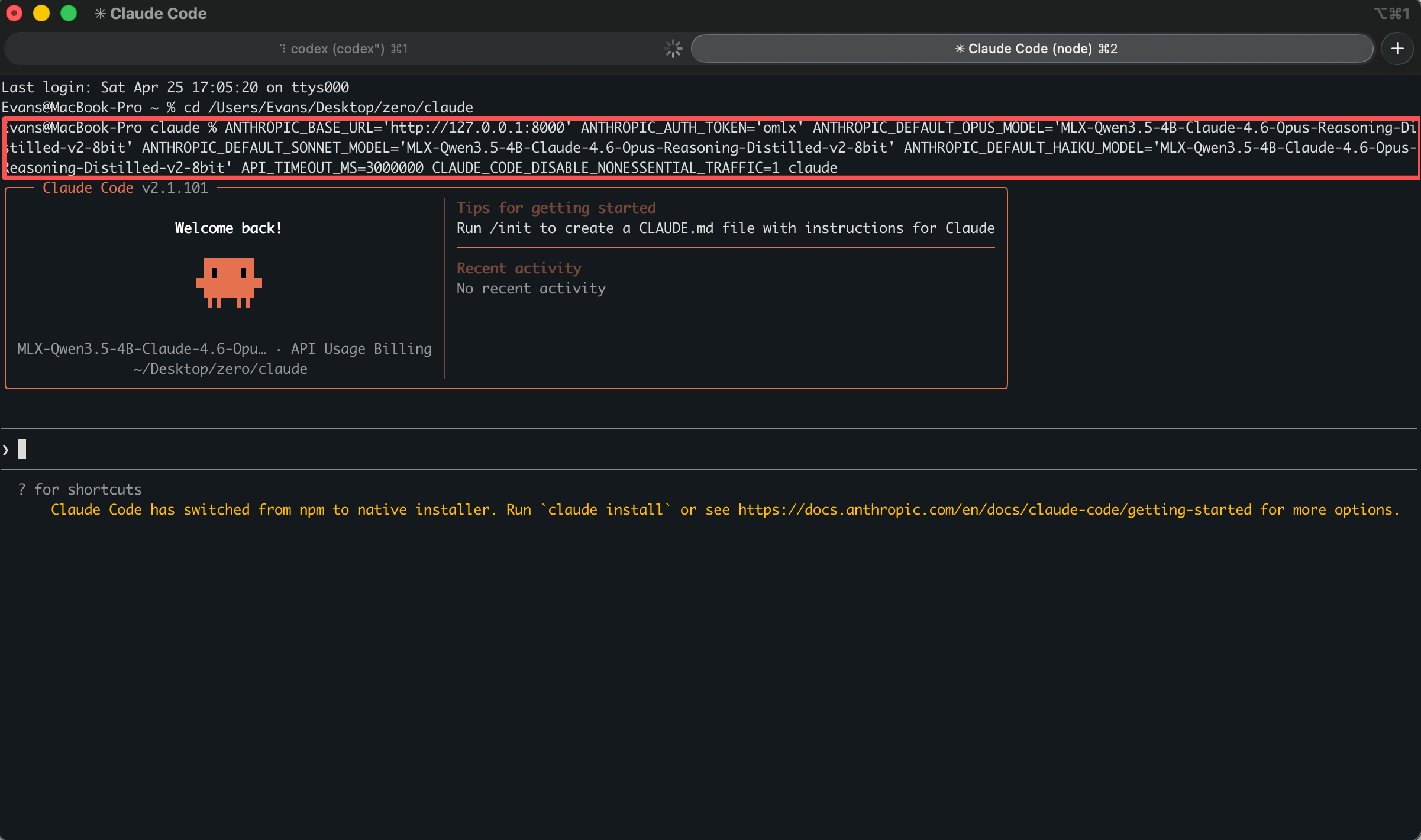
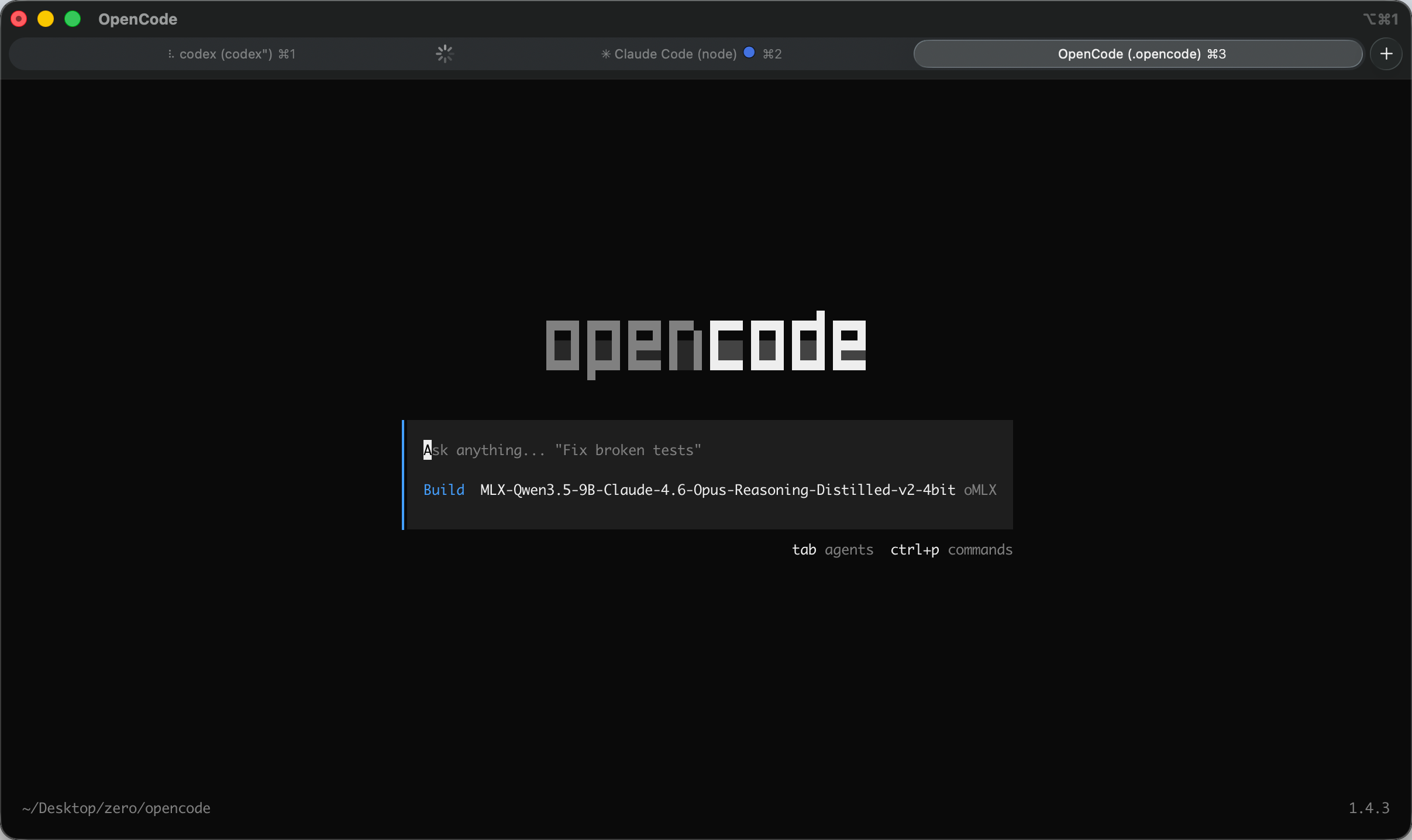
重要说明:推荐配置为 M 系列 Pro/Max + 64GB+ 内存,以获得最佳的使用体验。16GB 内存虽然可以运行,但可能会遇到内存不足的情况。
与传统方案对比
oMLX vs Ollama / LM Studio
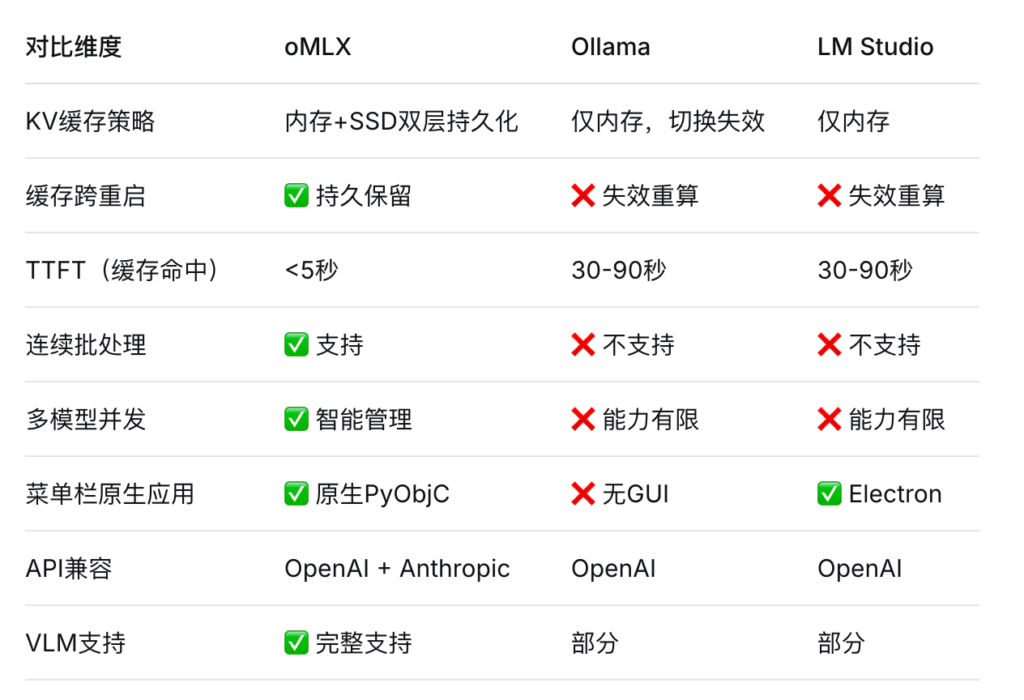
oMLX 的核心竞争力在于:
- 极速响应:TTFT 从 30-90 秒缩短到 5 秒以内
- 智能缓存:SSD KV 缓存技术实现上下文复用
- 高并发:连续批处理支持 8× 并发,吞吐量提升 4.14×
- 原生体验:非 Electron 构建的系统原生应用
- 完全开源:Apache 2.0 许可证,透明可控
最大的区别就是缓存机制:
Ollama和LM Studio的KV缓存都是放在内存里的,而且一旦对话的上下文变化,比如你用Claude Code的时候,它会不断地修改上下文,加工具调用的结果,这时候整个缓存就直接失效了,下次还要重新计算一遍,这就是为什么你会等半天。
而oMLX的缓存是块级的,持久化到SSD,不管上下文怎么变,只要有相同的前缀,就能直接复用缓存,不用重新算,这就是它能把首响从90秒降到5秒的核心原因。
而且oMLX专门针对Claude Code这类AI编码工具做了优化,比如SSE keep-alive防止长请求超时,上下文缩放让小模型也能配合Claude Code用,这些都是其他工具没有的。
oMLX 不仅是一个性能强大的 LLM 推理引擎,更通过其创新的缓存机制和友好的交互设计,解决了本地部署大模型的实际痛点。如果你拥有一台 Apple Silicon Mac,并希望在本地高效、便捷地运行大模型,oMLX 无疑是一个非常值得尝试的选择。
如果你有一台Apple Silicon Mac,并且正在寻找一个高效、易用的本地LLM推理方案,oMLX值得你立即上手体验。它很可能就是那块让Mac变身私人AI数据中心的最后拼图。
快速入口:
- GitHub仓库:https://github.com/jundot/omlx
- 官方网站:https://omlx.ai/
- 直接下载DMG:https://github.com/jundot/omlx/releases
快去试试吧,然后把你的Mac菜单栏交给oMLX——相信你也会成为它的忠实用户。